目次
・大数の弱法則
・コイントス
カヤ
今回は大数の弱法則を解説しよう。
大数の弱法則
ナユミ
大きな数が弱い法則?どういうもの?
カヤ
大数の弱法則とは次の定理のことだ。
\[ 大数の弱法則\]
確率空間 \( \left( \Omega , \mathcal P \rm \left( \Omega \right) , \it P \rm \right) \) のある確率変数を \( X \) とする。\( X \) と同一の確率分布に従う \( \left( \Omega , \mathcal P \rm \left( \Omega \right) , \it P \rm \right) \) の \( n \) 個の確率変数 \( X_1 , \ X_2 , \ldots , \ X_n \) の積における確率変数
\[ Y_n = \frac{X_1}{n} + \frac{X_2}{n} + \cdots + \frac{X_n}{n}\]
について、任意の \( \epsilon \gt 0 \) に対して、
\[ \lim _{n \to \infty} P \left( \left| Y_n - E(X) \right| \geq \epsilon \right) = 0 \]
が成り立つ。これを大数の弱法則と呼ぶ。
この定理の意味についてですが、
\[ Y_n = \frac{X_1 + X_2 + \cdots + X_n}{n}\]
とも表せるため、
\( Y_n \) は \( n \) 個の確率変数 \( X_1 , \ X_2 , \ldots , \ X_n \) の平均です。
\( E(X) \) はこれらの確率変数と同じ確率分布を持つ確率変数 \( X \) の期待値なので、
大数の弱法則はこの期待値と確率変数の平均値との間にズレが生じる確率が \( n \) を限りなく大きくすると0に限りなく近づくことを表しています。
この定理の証明は次の通りで、前回やったチェビシェフの不等式を使います。
この定理の証明は次の通りで、前回やったチェビシェフの不等式を使います。
\[ \begin{align}
E \left( Y_n \right) &= E \left( \frac{X_1}{n} + \frac{X_2}{n} + \cdots + \frac{X_n}{n} \right) \\\\
&= E \left( \frac{X_1}{n} \right) + E \left( \frac{X_2}{n} \right) + \cdots + E \left( \frac{X_n}{n} \right) \\\\
&= \frac{1}{n} \cdot \left\{ E \left( X_1 \right) + E \left( X_2 \right) + \cdots + E \left( X_n \right) \right\} \\\\
\end{align}\]
ここで、\( X_1,\ X_2,\ \ldots , \ X_n \) はいずれも \( X \) と同じ確率分布に従うから、これらの期待値はすべて等しい。すなわち、
\[ E(X) = E \left( X_1 \right) = E \left( X_2 \right) = \cdots = E \left( X_n \right)\]
が成り立つ。従って、
\[ \begin{align}
E \left( Y_n \right) &= \frac{1}{n} \cdot \left\{ E \left( X_1 \right) + E \left( X_2 \right) + \cdots + E \left( X_n \right) \right\} \\\\
&= \frac{1}{n} \cdot \left\{ E \left( X \right) + E \left( X \right) + \cdots + E \left( X \right) \right\} \\\\
&= \frac{1}{n} \cdot n E(X) \\\\
&= E(X)
\end{align}\]
また、\( X_1,\ X_2,\ \ldots , \ X_n \) はいずれも \( X \) と同じ確率分布に従うから、これらの分散はすべて等しい。すなわち、
\[ V(X) = V \left( X_1 \right) = V \left( X_2 \right) = \cdots = V \left( X_n \right)\]
ゆえに、任意の \( \epsilon \gt 0 \) に対して、チェビシェフの不等式より、
\[ \begin{align}
P \left( \left| Y_n - E(Y_n) \right| \geq \epsilon \right) &= P \left( \left| Y_n - E(X) \right| \geq \epsilon \right) \\\\
& \leq \frac{V(Y_n)}{\epsilon ^2} \\\\
&= \frac{V(\frac{X_1}{n} + \frac{X_2}{n} + \cdots + \frac{X_n}{n})}{\epsilon ^2} \\\\
&= \frac{V(X_1 + X_2 + \cdots + X_n)}{\epsilon ^2 n^2} \\\\
&= \frac{V \left( X_1 \right) + V \left( X_2 \right) + \cdots + V \left( X_n \right)}{\epsilon ^2 n^2} \\\\
&= \frac{V \left( X \right) + V \left( X \right) + \cdots + V \left( X \right)}{\epsilon ^2 n^2} \\\\
&= \frac{n V \left( X \right)}{\epsilon ^2 n^2} \\\\
&= \frac{V \left( X \right)}{\epsilon ^2 n} \\\\
\end{align}\]
よって、
\[ 0 \leq P \left( \left| Y_n - E(X) \right| \geq \epsilon \right) \leq \frac{V \left( X \right)}{\epsilon ^2 n} \]
が成り立ち、この不等式の \( n \to \infty \) の極限をとると、
\[ 0 \leq P \left( \left| Y_n - E(X) \right| \geq \epsilon \right) \leq 0 \]
となる。よって、
\[ \lim _{n \to \infty} P \left( \left| Y_n - E(X) \right| \geq \epsilon \right) = 0 \]
が成り立つ。
前半は
\[ X_1,\ X_2,\ \ldots , \ X_n \]
がいずれも \( X \) と等しい確率分布を持つことを用いて \( E(Y_n) = E(X) \) を示しています。
分散についても、同様のテクニックを使って
\[ V(X) = V \left( X_1 \right) = V \left( X_2 \right) = \cdots = V \left( X_n \right)\]
を示しています。
後半はチェビシェフの不等式を使って、問題の確率が \( n \) に反比例する式以下であることを示して、その極限をとって定理を証明しています。
後半はチェビシェフの不等式を使って、問題の確率が \( n \) に反比例する式以下であることを示して、その極限をとって定理を証明しています。
カヤ
それじゃあ、大数の弱法則の理解を深めるために、この法則が実際のデータで成り立っているかどうか、コイントスを例に確かめてみよう。
コイントス
コイントスは、表と裏がそれぞれ確率 \( \frac{1}{2} \) で出ると仮定します。
表に1、裏に0の確率変数の値を対応させると、期待値は
\[ E(X) = 1 \cdot \frac{1}{2} + 0 \cdot \frac{1}{2} = \frac{1}{2}\]
になるので、\( Y_n \) はコインをたくさん投げれば \( \frac{1}{2} \) に近づいていくと予想されます。
ナユミ
コイン投げの結果はどうなったの?
カヤ
今回は500円玉を200回投げてみた。横軸にコインを投げた回数、縦軸に \( Y_n \) をとったグラフがこれだな。
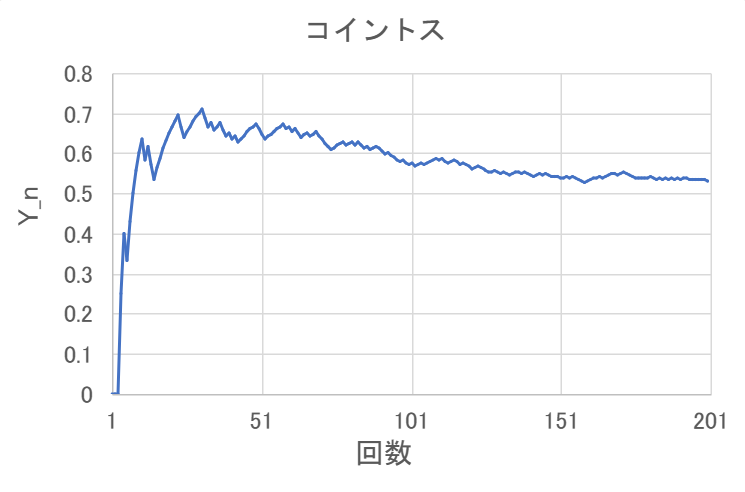
200回投げた時点での \( Y_n \) の値は0.53で、まだ0.5とは6%ほどズレていますが、もっとたくさんコインを投げれば、\( Y_n \) はより0.5に近づいていくと予想されます。
ナユミ
コイントス200回お疲れ様ね。
カヤ
どうも。じゃあ今回はここまでにしよう。
参考:
[1] A.N.Kolmogorov 著、Nathan Morrison 英訳、FOUNDATIONS OF THE THEORY OF PROBABILITY、CHELSEA PUBLISHING COMPANY NEW YORK、1950年
前の記事
第19話
チェビシェフの
不等式
チェビシェフの
不等式
次の記事

第21話
ルンゲ=クッタ法
ルンゲ=クッタ法